Anonimiseren in het nieuws
Door John van Nes.
Onlangs was het in het nieuws. Nieuwsuur meldt dat Buitenlandse Zaken opnieuw per abuis staatsgeheimen lekt.
Per ongeluk zijn staatsgeheimen over het Nederlandse hulpprogramma aan Syrische strijdgroepen naar buiten gebracht. Het is de tweede keer dat het ministerie deze fout maakt.
De fout is gemaakt bij de behandeling van een WOB-verzoek welke Nieuwsuur en Trouw hebben ingediend over het steunprogramma aan Syrische rebellen. Bij het verstrekken van documenten in november 2018 bleken daar per abuis staatsgeheimen tussen te zitten, zoals namen van strijdgroepen, maar ook van Nederlandse diplomaten en van een geheim agent.
De Open Source Intelligence methode
Om meer informatie te halen uit de rapporten is de Open source intelligence (OSINT) methode toegepast. Een voorbeeld is het achterhalen van de waarheid achter de MH17-ramp. Het onderzoekscollectief Bellingcat en het Openbaar Ministerie hebben puzzelstukken gevonden via open source intelligence, waarvoor ze de mogelijkheden van het internet tot het uiterste benutten. In het artikel op de Correspondent op 21 juni 2019 legt Dimitri Tokmetzis goed uit hoe iedereen kan leren om digitaal onderzoek te doen.
De uitdaging voor WOB-verzoeken.
Als team zijn we dagelijks bezig om onze klanten te helpen om WOB verzoeken sneller en beter af te kunnen handelen. Dus voor ons interessant om hiervan te leren. De uitzending en toelichting geeft voldoende informatie om te bezien hoe de instructies voor het anonimiseren verbeterd kunnen worden. En laten we eerlijk zijn, deze fouten kunnen we nog niet voorkomen met onze CARP-E oplossing voor automatisch anonimiseren. CARP-E kan veel, maar er blijft menselijk inzicht en creativiteit nodig om delen van informatie te combineren.
Leerpunten
Uit ieder bericht in het nieuws zijn punten voor verbetering te halen. De leerpunten die wij genoteerd hebben zijn hieronder kort vermeld met wat voorbeelden uit de uitzending.
Duplicaten
Voorkom duplicaten van documenten. Dit scheelt natuurlijk werk maar hiermee wordt voorkomen dat dezelfde documenten anders beoordeeld worden.

Foto’s
Op foto’s moeten alle teksten verwijderd worden. Let hierbij zeer goed op niet-westerse talen (Arabisch, Chinees etc.). De teksten kunnen voorkomen op vlaggen, gebouwen, auto’s etc.

Foto’s: alles zwartlakken.
Soms kan zelfs van een klein deel van een foto mensen, groepen of locaties herleid worden door zoektochten op internet. Zoals de bovenkant van de foto hiernaast. Volledig zwartlakken van een foto is dan de enige remedie.
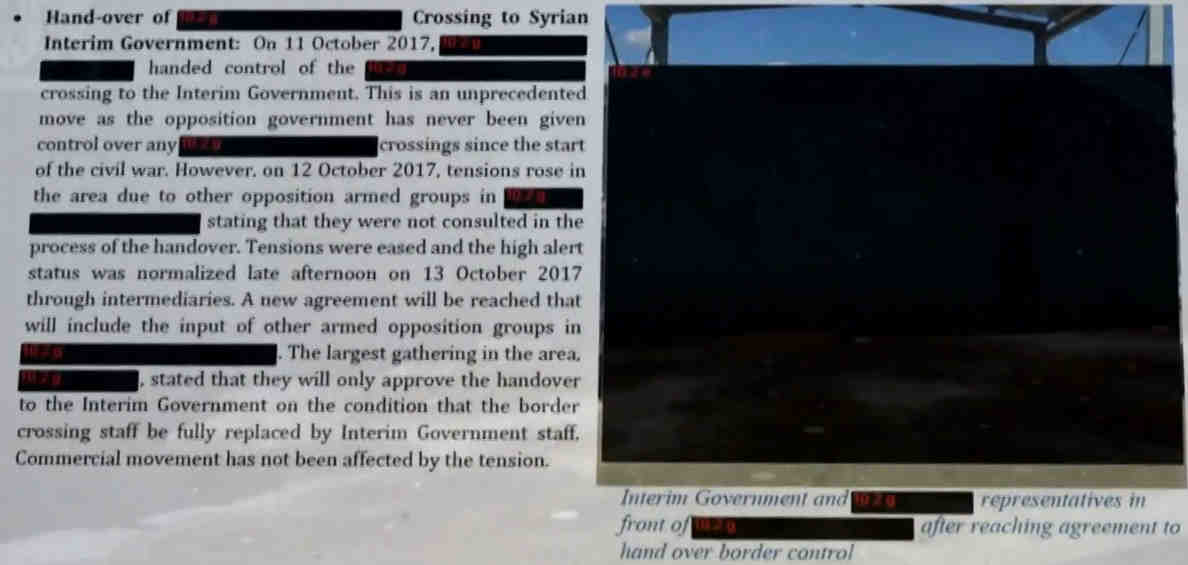

Namen
Wees consequent met het verwijderen van (bedrijfs)namen. Indien een bedrijfsnaam in een document zwartgelakt wordt, moet dat gedaan worden in alle te publiceren documenten.
In de foto hiernaast is het bedrijf "Creative" bovenin vergeten zwart te lakken. In het onderste document is de bedrijfsnaam wel verwijderd.

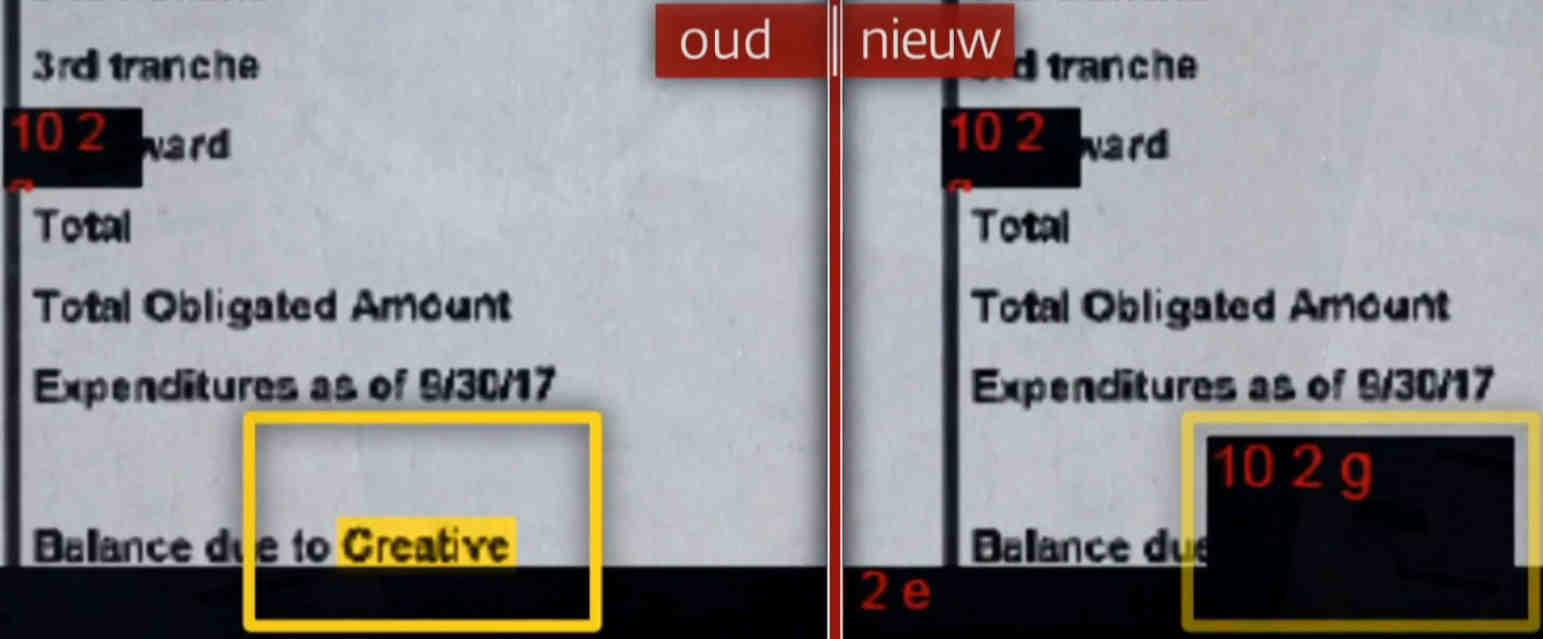
Internet citaten
Citaten van het internet kunnen opgezocht worden en leiden tot een bron.
Op basis van het citaat in een document (afbeelding rechts) is de bijbehorende video is na wat zoekwerk te vinden op internet (2e afbeelding).


Genoeg uitdagingen dus voor Anonimiseren.
Het specialisme blijft daarmee nog mensenwerk. Het bulkwerk en vooral het zorgen voor consistentie en eenduidigheid in anonimiseren kan wel uit handen genomen worden.